Combine a fizzing baking soda and vinegar reaction with balloon play with this easy-to-set-up balloon science experiment for kids. Find out how to blow up a balloon with baking soda and vinegar. Grab a few simple ingredients from the kitchen, and you have fantastic chemistry for kids.

Baking Soda and Vinegar Balloon Experiment
Set up this fun balloon experiment as a demonstration for younger students to observe cause and effect, or for group work or individually with older students to explore chemical reactions.
💡 Don’t have vinegar for this experiment? Try a citric acid like lemon juice, and check out our citric acid and baking soda experiment here.
Watch the video:
Supplies:
- Baking Soda
- Vinegar
- Empty Water Bottles
- Balloons
- Measuring Spoons
- Funnel {optional but helpful)

Experiment Set Up
Step 1. Blow up the balloon a bit to stretch it out first, and then use the funnel and teaspoon to add baking soda to the balloon. We started with two teaspoons and added a teaspoon for each balloon.

Step 2. Fill the container with vinegar halfway.
Step 3. When your balloons are all made up, attach them to the containers making sure you have a good seal!
Step 4. Next, lift up the balloon to dump the baking soda into the container of vinegar. Watch your balloon blow up!
💡 To get the most gas out of it, we swirled around the container to get it all going!
Optional Art: Go ahead and use a sharpie to draw emojis, shapes, or fun pictures on your balloons before filling them with baking soda. See our Valentine heart version and Halloween balloon experiment.
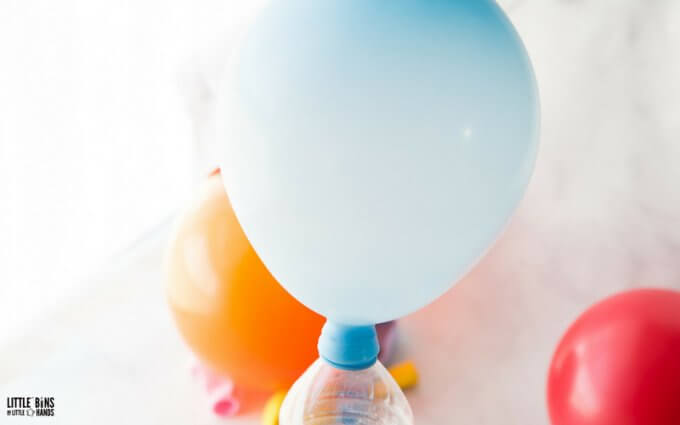
What Makes The Balloon Inflate?
The science behind this baking soda and vinegar balloon science experiment is a chemical reaction between an acid and base. The base is the baking soda and the acid is vinegar. When the two ingredients mix, the balloon baking soda experiment gets its lift!
They react together to form sodium acetate, water and a gas called carbon dioxide, or CO2. As the gas tries to leave the plastic container, it goes up into the balloon because of the tight seal you have created.
For younger students: Talk about states of matter – you have a solid (baking soda), liquid (vinegar) and a gas (carbon dioxide).
The gas has nowhere to go and is pushing against the balloon it blows it up. Similar to how we exhale carbon dioxide when we blow up balloons ourselves.
We love exploring simple chemistry you can do at home or in the classroom. Science that isn’t too crazy but is still lots of fun for kids! You can check out more cool chemistry experiments.
Read more about the science behind baking soda and vinegar experiments.
Turn It Into A Science Project
Here are some ways to turn this balloon activity into a true science experiment with clear variables, hypotheses, and data collection:
Choose A Question To Test:
- How does the amount of baking soda affect the size of the balloon?
- How does the temperature of vinegar influence the speed of balloon inflation?
- What type of vinegar produces the most gas?
Use Precise Measurements:
- Use a measuring cup or scale to quantify the vinegar and baking soda.
- Measure the balloon’s circumference with a tape measure or string.
- Use a stopwatch to time how long it takes for the balloon to fully inflate.
Record Date and Repeat If Needed: Learn more about applying the scientific method!

More Fun Science Experiments To Try
- Volcano Model: Make an erupting volcano with baking soda and vinegar.
- Pop Rocks and Soda: Here is another fun way to blow up a balloon using soda and pop rocks.
- Bath Bomb Science: Mix baking soda, and citric acid, and test how water activates the fizzing reaction.
- Lemonade: Make fizzing lemonade with lemons and baking soda.
- Lava Lamp: Create a homemade lava lamp using oil, water and Alka Seltzer tables.
- Test Acids and Bases: Make a natural indicator from red cabbage to test pH.






Helpful Science Resources To Get You Started
Here are a few resources that will help you introduce science more effectively to your kiddos or students and feel confident yourself when presenting materials. You’ll find helpful free printables throughout.
- Best Science Practices (as it relates to the scientific method)
- Science Vocabulary
- 8 Science Books for Kids
- All About Scientists
- Free Science Worksheets
- Science Supplies List
- Science Tools for Kids
- Scientific Method for Kids
- Easy Science Fair Projects
- Citizen Science Guide
- Join us in the Club
Printable Science Projects For Kids
If you’re looking to grab all of our printable science projects in one convenient place plus exclusive worksheets and bonuses like a STEAM Project pack, our Science Project Pack is what you need! Over 300+ Pages!
- 90+ classic science activities with journal pages, supply lists, set up and process, and science information. NEW! Activity-specific observation pages!
- Best science practices posters and our original science method process folders for extra alternatives!
- Be a Collector activities pack introduces kids to the world of making collections through the eyes of a scientist. What will they collect first?
- Know the Words Science vocabulary pack includes flashcards, crosswords, and word searches that illuminate keywords in the experiments!
- My science journal writing prompts explore what it means to be a scientist!!
- Bonus STEAM Project Pack: Art meets science with doable projects!
- Bonus Quick Grab Packs for Biology, Earth Science, Chemistry, and Physics








Need more info on experiments. Thanks, Miranda
What information would you like?
thanks a lot very funny experiment
Your welcome!
(I was thinking that the pint bottle was going to blow up I got really scared first time I saw a science magic) but I can make smoke come out of my mouth it is very simple
I’m doing a Science Fair Project on this, but I don’t know and how to do the table and graphs, like the data and stuff. Can you help me?
And it’s due May 18, 2016 🙁
this is cool thanks you verry much
Your welcome! Try drawing on the balloons too!
Does the size of the container or size of balloon have any affect on how the balloon will blow up?
Yes, it will because of the space the gas has to fill once the baking soda and vinegar are combined. Great experiment to try different sizes using the same amounts of both vinegar and baking soda.
my team did the balloon inflating thing and it was fun
Is it safe for kids to do this experiment in school
I would think it would be as it is just baking soda and vinegar. You would need to use your best judgement of course. We have never had a balloon explode.
hi this is STEM project .
can anyone explain how to connect – T technology E Engineering M mathematics through this experiment .
thanks in advance
I will look into my information. Remember a STEM project does not need to contain each of the 4 pillars of STEM but at least two. I can tell you we used math {measuring} and science {chemical reaction}.
Definitely is cool
i love yo stuff
If we wanted to use this for a science fair project what would the Question asking be?
How much baking soda/vinegar is needed to inflate balloon completely. Or, which acid is better vinegar or lemon juice? Do different shape balloons fill better?
We just did this experiment, but we only used one balloon. My kids are 2.5, 4 and 7 so we have a range of ability levels, but I wanted to add my kids’ favorite part! We took the balloon off the bottle and tied it shut, careful not to lose the gas. And then I blew a balloon up the same size, I asked them which one they thought would hit the ground first as I held them even in the air. Try it out!!
That’s awesome! We will def have to try that. What a great idea!
Where did you find your containers to hold the baking soda and vinegar?